
martes, 31 de mayo de 2011
JPA : OneToMany / ManyToOne

Hasta el momento no lo habíamos mencionado, pero existen básicamente dos formas de asociación:
- Las basadas en valores simples.
- Las basadas en colecciones de valores.
Dentro de esas formas de asociación, existen cuatro formas de “mapeo”:
- Relación One-To-One (valores simples). Este tema lo tratamos en un post anterior.
- Relación Many-To-One (valores simples)
- Relación One-To-Many (colecciones de valores)
- Relación Many-To-Many (colecciones de valores)
En este post trataremos el tema de las relaciones One-to-Many y Many-to-One (caso típico de las aplicaciones que manejan cabecera y detalle).
Si este es el esquema de base de datos, observa que la orden tiene una llave foránea que es el CUST_ID (de la tabla TBCUSTOMER) para poder identificar de quien es la orden:

Las entidades respectivas tendrían el siguiente formato:

Es importante tener en cuenta que:
a) El lado “many-to-one” siempre es el lado “owner” de la relación. En consecuencia, la anotación @JoinColumn debe estar en dicho lado.
b) El lado “one-to-many” es el lado “inverso”, por lo que el elemento “mappedBy” debe ser utilizado en este lado.
El atributo "optional" en valor "false" indica que la relación siempre debe existir: es decir, no puede haber órdenes sin cliente asociado.
La anotación @JoinColumn especifica en el atributo "name" el nombre de la columna en la tabla "owner" de la relación. Mientras que el atributo "referencedColumnName" especifica el nombre de la columna en la tabla destino.
En la clase "Customer1" nota que existe un atributo "orders" que es una colección de órdenes que se cargarán de manera EAGER.
TIP: para evitar referenciar dentro de nuestros programas a cada atributo de la entidad, creamos un método "toString" que nos retorne la concatenación de los valores. Por ejemplo para la entidad "ORDERS" agregamos el método siguiente (aparte de los setter/getter ):

EJEMPLO 1: Fragmento de Programa main que lee desde el Cliente ( para la PK 1000 ) la relación One-To-Many. Este fragmento busca al cliente con PK = 1000 y al referenciar al atributo "orders", automáticamente jala las órdenes relacionadas.

EJEMPLO 2: Fragmento de Programa main que lee todas las órdenes para el cliente con PK = 1000. Es la relación Many-To-One

Si observas la consola de tu IDE, verás las sentencias SQL que se ejecutan ( siempre que la opción de debug esté habilitada en tu persistence.xml ).
¿ que te pareció ? ... Por favor comenta y opina.
JPA : Lazy vs. Eager

Las entidades y sus atributos pueden ser cargados de dos formas:
- LAZY: Cuando se cargan de forma “perezosa”, es decir, se cargan en el momento en que se requieren.
- EAGER: Cuando se cargan de forma “proactiva”, es decir, al momento de cargar la entidad “owner” de la relación.
Si ves televisión ... acuerdate de este programa para asociarlo con estos conceptos :

En términos de JPA, se usa el atributo “fetch” acompañando a la anotación de la relación e indicando el valor de FetchType.LAZY o FetchType.EAGER.
Hay que indicar que las opciones de LAZY o EAGER se comportan diferente según estemos en un ambiente Java SE o EE ( y según la implementación JPA que usemos )... para eso leer la documentación nos servirá de mucho.
Cuando se trabaja con EclipseLink en un entorno Java EE hay una facilidad que permite "mejorar" (se conoce como "weaving") las clases java de forma automática.
Cuando se usa EclipseLink en un ambiente donde el "weaving" no es automático ( como en Java SE ) existen dos opciones:
- La primera y más fácil es usar el parámetro -javaagent como argumento para la máquina virtual Java indicando la ruta hacia el eclipselink.jar.
- La segunda forma es usando el "static weaver" que es una nueva compilación que debe hacerse sobre las clases ya compiladas por la JVM.
Es importante analizar esto, porque puede darse el caso de definir una relación OneToMany como LAZY y al momento de ejecutar la aplicación podríamos observar que se cargan todas las dependencias de forma automática.
JPA : Generación de Llave Primaria

Además de la anotación @Id se emplea la anotación @GeneratedValued con el atributo "strategy". Básicamente hay cuatro valores para el atributo:
- strategy=GenerationType.AUTO
- strategy=GenerationType.TABLE
- strategy=GenerationType.SEQUENCE
- strategy=GenerationType.IDENTITY
El AUTO le dice a JPA que busque la mejor forma de generación de secuencias. Dependiendo de la base de datos a usar se puede manejar "secuencias" (oracle) o "autoincrementos" (MySQL). Para no complicarnos mucho, en este post sólo mencionaremos el uso de la opción TABLE, que es una buena alternativa cuando queremos controlar la generación de la secuencias en una tabla ( algo así como una tabla de correlativos ).
Forma de utilización #1:
Si sólo se especifica la anotación sin indicar la tabla, JPA busca (o genera ) una tabla llamada "sequence". La tabla requiere de dos columnas: una conteniendo el identificador para generar la secuencia y la otra columna contiene el último valor generado. Cada fila de la tabla es un generador diferente para los ID’s.
Ejemplo:

Forma de utilización #2:
¿ Qué sucede si deseamos indicar una tabla específica ?. Debemos agregar una anotación más: @TableGenerator
Ahora debemos indicar algunas características de la tabla (que si bien sigue manteniendo la estructura mencionada en la forma de uso #1 ), requiere el "mapeo" de algunas cosas:

A diferencia de la estrategia IDENTITY, en ésta estrategia el valor de la PK ya está disponible desde el momento en que se hace el persist.
¿ Que opinas ?
Por favor prueba las otras estrategias de generación de PK y coloca tus comentarios.
domingo, 29 de mayo de 2011
Evento Cibertec
El día de hoy estuvo un poco difícil pues tuve que dar una charla para recordar algunos temas necesarios para la preparación del examen que rendirán para el proyecto de una fábrica de software de una importante empresa local.
Los temas tratados fueron:
- Arquitectura de aplicaciones JEE
- Enterprise Java Beans ( EJB ) : Session, Managed y Message-Driven
- JPA ( recuerden los fetch de tipo LAZY y EAGER ).
- JSF ( acuerdense de los archivos de configuración )
- SOA y Web Services ( SOAP, WSDL y UDDI )
Les deseo suerte en su examen y ojalá logren una plaza.
Saludos
sábado, 28 de mayo de 2011
JPA En castellano
Aqui les dejo una referencia de JPA ( un resumen bastante bueno desde mi punto de vista ).
Dar click aquí ( SCRIBD ).
saludos
viernes, 27 de mayo de 2011
Haciendo experimentos ... ahora tambien estamos en Facebook ... simplemente presiona el botón que está más abajo de la página.
Dado que no escriben mucho en el blog, es probable que escriban más en el muro de facebook ....así que ya no hay pretexto para no leer y estudiar.
Buen Fin de semana.
EC #2 : Imágenes del Evento
El día de hoy Jueves tuvimos la segunda evaluación continua del curso.
Algo realmente espectacular nunca antes visto por estos lares es que fue exactamente lo mismo de la primera continua (recuerden que a cada uno le entregué un archivo con correcciones) ... solo que usando JPA ... El objetivo era ver como el uso de JPA nos facilita la generación de código debido a que ahora escribimos menos sentencias de acceso a la BD.
Algo realmente espectacular nunca antes visto por estos lares es que fue exactamente lo mismo de la primera continua (recuerden que a cada uno le entregué un archivo con correcciones) ... solo que usando JPA ... El objetivo era ver como el uso de JPA nos facilita la generación de código debido a que ahora escribimos menos sentencias de acceso a la BD.
Pese a ello ... aquí un testimonio gráfico de la seriedad con que los alumnos enfrentan el desafío de usar por primera vez JPA ...
El grupo 1:


El grupo 2:

Obviamente el grupo 2 siempre sale más sonriente ... ¿ será que estudian más ? ¿ o quizás han descubierto alguna forma de copiar que aun desconozco ? ... Si alguien sabe algo al respecto pasen la voz (hay puntos extras de recompensa por el dato ) ...
Tambien aprovecho el post para informar que se aproxima el examen parcial ... no se olviden del lápiz, lapicero y borrador ( y sobre de todo ... de estudiar !!! )
Saludos
PD: No se olviden de contestar la encuesta de la EC#2 en el lado izquierdo de la página.
PD: No se olviden de contestar la encuesta de la EC#2 en el lado izquierdo de la página.
martes, 24 de mayo de 2011
JPA : Store Procedures y demás hierbas

Anoche estuve jugando Operation7 hasta tarde ( es parecido a Counter Strike o a Combat Arms hasta que banearon a todo latinoamerica porque nuestras redes son lentas ). Entonces, para no aburrirme ahora y que me de sueño ( pese a los cafes del Starbucks ! ) , debo mantener mi CPU en actividad.
En este post hablaré sobre JPA y los famosos Store Procedures que muchos han estado preguntando. Aunque hay una discusión acerca de si la base de datos debe tener lógica de negocio o no, lo cierto es que al colocar store procedures en el motor, la portabilidad del sistema se echa por la borda: todos los códigos SPL no son iguales y por tanto hay que invertir tiempo en adecuarlos.
Particularmente prefiero que cada cosa cumpla la función para la que fue creada : Base de datos para datos y servidor de aplicaciones para lógica de negocio. Pero a veces en situaciones reales, donde mandan capitanes no gobiernan marineros.
No recuerdo de donde obtuve este código de una función MySQL de ejemplo ( pero reconozco que el código no es mío por tanto no aseguro que funcione bien ... solo lo tomo como ejemplo ). Lo que hace es calcular la diferencia de dos fechas.

Ahora el fragmento de programa main que ejecuta el código usando JPA. En el persistence.xml no será necesario colocar la definición de entidades (si es que no las usamos ).
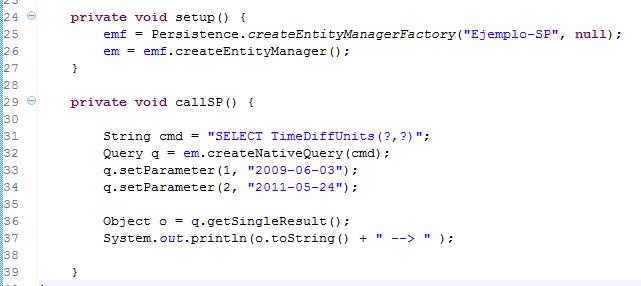
Observen que al tratarse de una función, se usa un .getSingleResult.
pero si se tratase de un Procedure que hace alguna operación, hay que hacer un .executeUpdate. Es más, requerirá colocarlo dentro de una transacción.
Observa tambien que al entity manager se le dice createNativeQuery y que la sintaxis que va dentro ( el comando a ejecutar ) dependerá del motor de base de datos que usemos.
La forma de "setear" los parámetros lo veremos en la semana 6 aunque puedes ir revisando el manual impreso.
¿ Que te pareció ? Opina y/o comenta.
Prueba otras formas.
Saludos.
domingo, 22 de mayo de 2011
JPA: Relaciones One To One

En este post comentaremos el tipo de relación de uno-a-uno que se aprendió durante los cursos de Anáisis y Diseño con UML.
Básicamente implica que una entidad está relacionada con otra, pero tiene sus bemoles:
- Existe la relación nomal (analiza este ejemplo ).
- Pero también existe la relación inversa (analiza este ejemplo ).
De esta forma, es posible consultar las entidades por los dos lados de la relación.
Este tipo de relación requiere de dos anotaciones:
- @OneToOne : para especificar las características lógicas de la relación
- @JoinColumn: para especificar las características físicas de la relación. Es decir, cuales son las columnas de JOIN de las tablas.
Descarga e importa esta base de datos MySQL y lee el siguiente PDF de la clase.
Hasta el momento sólo hemos visto como ejecutar sentencia de consulta usando la relación OneToOne.

TAREA: Intenta ejecutar una operación de PERSIST, MERGE o REMOVE.
Opina y/o comenta como te va con la tarea.
sábado, 21 de mayo de 2011
JPA : Troubleshooting #1
En este post hablaremos acerca de la configuración que debe tenerse en cuenta para que funcione una aplicación sin presentar un error del tipo siguiente:
Para ello, sabemos que en el archivo persistence.xml existe un tag llamado <persistence-unit> que tiene un atributo llamado "name". Dicho nombre debe coincidir exactamente con el que utilizamos en el programa Java para crear la factoría y después el EntityManager Sea en Java SE o en Java EE (es lo mismo).
Presten atención a la figura para mayor claridad :

Si no coinciden los nombres, aparecerá el error.
Saludos
viernes, 20 de mayo de 2011
JPA : Lecturas recomendadas
jueves, 19 de mayo de 2011
DAW-II : Recordatorio

Estimados lectores(alumnos) del blog, les recuerdo que la nota actitudinal tiene dos componentes básicos (aparte de los otros ya conocidos) :
- Participacion en clase.
- Lenguaje adecuado en clase.
Tengan en cuenta que es obligatorio participar en el blog (para ganar puntos), no sólo leyendo los post y bajando los archivos, sino tambien aportando comentarios, links a otros sitios con información que podamos compartir, etc.
Adicionalmente, si no desean registrar un comentario, pueden usar el formulario de contacto.
¡ Saludos !
miércoles, 18 de mayo de 2011
Apache Tomcat : Crear un dataSource
Para el proyecto del curso se pide usar Datasources. Tienen dos opciones:
- Lo hacen con WebSphere ( las instrucciones están en Post anteriores )
- Lo hacen con Tomcat ( esto deben haberlo visto en LP-2 ).
En el caso de Tomcat es mucho más "sencillo" crear un DataSource (acuerdate que el servidor debe estar detenido ).
En las opciones de configuración de Tomcat colocamos el driver de MySQL y lo removemos del folder WEB-INF\lib de nuestro proyecto.
Estando en Eclipse editamos el archivo context.xml

Y escribimos lo siguiente:

Reiniciarmos el servidor Tomcat y listo !!!!
Ojo que la aplicación debe llamar al nombre JDNI del DataSorce.
saludos
DAW-II : Avisos de Servicio Público

Aviso 2: No se olviden de llenar la encuesta académica parcial. Como es anónima pueden maletear al profesor ( no problem ...peace & love ).

martes, 17 de mayo de 2011
Introducción a JPA ( parte III )
Finalmente, hablaremos del ciclo de vida de una entidad como se aprecia en el gráfico siguiente:

Lo más saltante es que no podemos efectuar operaciones con la entidad si es que primero no la colocamos en estado "managed", es decir, si primero el Entity Manager no la tiene reconocida (o cargada ).
Por otro lado, cada evento que sucede en el Entity Manager ( las operaciones básicas sobre la entidad) generan o disparan una serie de acciones que se conocen como los "Callbacks" o Listeners.
Las anotaciones que proporciona JPA para manejar los “Callbacks” son:
- @PostLoad : Se ejecuta luego de un “refresh” a la entidad.
- @PrePersist: Se ejecuta antes de insertar la entidad.
- @PostPersist: Se ejecuta después de haber insertado la entidad.
- @PreUpdate: Se ejecuta antes de un update a la entidad.
- @PostUpdate: Se ejecuta después de un update a la entidad.
- @PreRemove: Se ejecuta antes de eliminar la entidad en la base de datos.
- @PostRemove: Se ejecuta después de haber eliminado a la entidad.
Dichas anotaciones las podemos colocar dentro de métodos de la misma entidad, en cuyo caso el método no recibe como parámetro a la entidad en sí.
O tambien, apuntar a otra clase que sea la que contenga a los métodos, en cuyo caso, los método reciben como parámetro a la entidad. Para ello hay que usar la anotación @EntityListener en la entidad para apuntar a la clase externa.
Revisa el manual ( o este PDF ) para ver los ejemplos ( pág 57 ...creo ).

Deja tus comentarios
Proyecto 2011-I
Aqui les dejo el proyecto para este ciclo con las instrucciones.
Es bastante sencillo, pero requiere investigación en algunos aspectos ( recuerden los objetivos educacionales de la carrera ). Obviamente se debe trabajar tambien en el "arte" ( hojas de estilo, colores, efectos Ajax, etc. No vale utilizar plantillas del laboratorio.

El documento incluye los plazos de entrega y los puntajes acumulativos. Tengan en cuenta que las fechas son únicas ( no existe el concepto de Hora Cabana ni nada que se le parezca ).
Para cualquier consulta coloquen el comentario respectivo de tal manera que todos puedan ver las dudas y respuestas.
¡ Saludos !
lunes, 16 de mayo de 2011
Una reflexión ...
Como mencionabamos en la primera sesión, estuve reflexionando sobre los resultados de esta EC#1. He extraído de este post algunas ideas base:
- El examen escolástico ( osea ... el de mis épocas de escolar, ya se imaginarán cuantos años tengo ) se basa en la mera memorización mecánica de información.
- Un docente que cree que ha cumplido su función al lograr que sus alumnos repitan de manera uniforme lo que él ha dicho, no es un educador, es meramente una grabadora ( por tanto no me considero una grabadora ...)
- Una buena prueba facilitadora, busca que el estudiante muestre su comprensión, creatividad y capacidad de análisis, crítica y desarrollo personal.

No pongo nada de la "U" o "Alianza" porque sino, lloramos juntos ... JA JA JA
Recuerdo que les dije que si en la clase les enseño que 1 + 1 = 2 ... en el examen no les iba a preguntar cuando es 1 + 1 ... sino que podría preguntar cuanto es 3-1 o 4-2 ..... para que PIENSEN .... es más , pueden usar manuales, CD, libros, etc etc etc ...
Espero sus comentarios al respecto y su aporte a la encuesta respectiva.
Saludos
viernes, 13 de mayo de 2011
EC #1: Imagenes del evento
Y llegamos a la semana 3, correspondiendo la primera evaluación del avance académico.
Los temas fueron básicamente validaciones con Struts 2 y verificar y grabar datos usando JDBC ( algo sencillo ). Para evitarnos complicaciones, usamos Eclipse + Tomcat. Aquí está el texto de la evaluación ( click aquí ).
Aquí las imágenes del primer grupo :


Por la seriedad que se aprecia ...creo que no hicieron la tarea.
En cambio, los del segundo grupo parece que sí hicieron la tarea:

En ambos casos ... aun no hay notas ... así que tengo trabajo para el fin de semana.
Por favor, envíen su voto a la encuesta del lazo izquierdo.

Los temas fueron básicamente validaciones con Struts 2 y verificar y grabar datos usando JDBC ( algo sencillo ). Para evitarnos complicaciones, usamos Eclipse + Tomcat. Aquí está el texto de la evaluación ( click aquí ).
Aquí las imágenes del primer grupo :


Por la seriedad que se aprecia ...creo que no hicieron la tarea.
En cambio, los del segundo grupo parece que sí hicieron la tarea:

En ambos casos ... aun no hay notas ... así que tengo trabajo para el fin de semana.
Por favor, envíen su voto a la encuesta del lazo izquierdo.

Hummm ... falló Blogger
Blogger ha estado inactivo desde ayer ... dicen que han recuperado los Post pero la verdad es que se ha perdido el último que puse acerca del uso del orm.xml.
Tendré que escribirlo nuevamente .... ( snif !!!! )
Buen fin de semana.

miércoles, 11 de mayo de 2011
Bono: JPA y archivo orm.xml
En el post anterior mencioné que particularmente prefería colocar las anotaciones dentro de las clases Java y usar el archivo persistence.xml porque me parece más claro a la hora de dar mantenimiento a las aplicaciones.
Sin embargo, la otra opción es usar el archivo de "mapeo" llamado orm.xml que se ubica en el mismo directorio que el anterior, es decir, en META-INF.
¿ Cual es la diferencia ? ...
- que si no tenemos un wizard que haga las cosas ... tendremos que escribir el contenido del archivo a mano.
- que quitamos todas las anotaciones de la clase Java y ahora las registramos como "tags" XML dentro del orm.xml
¿ Ver para creer ? , mira el siguiente gráfico y trata de repetirlo con el ejemplo dado en clase:

Ahora, ¿ cual de las dos maneras prefieres ?
Opina ... porque esto creo que no está en el manual. ¿ Lo has revisado ?
Introducción a JPA ( parte II )
En clase vimos una pequeña aplicación Java SE utilizando JPA.
Aquí les dejo un pequeño tutorial que explica el contenido del archivo de configuración persistence.xml así como el manejo de librerías en Eclipse (lo mismo aplica para Rational ).
Este tutorial introduce el concepto de 3 anotaciones (revisa el manual del curso):
Este tutorial introduce el concepto de 3 anotaciones (revisa el manual del curso):
- @Entity
- @Table
- @Id
Recuerda que en JDBC e Ibatis las sentencias DML (Data Manipulation Language) trabajan sobre "Tablas" y son:
- SELECT
- INSERT
- DELETE
- UPDATE
Mientras que en JPA, las sentencias DML trabajan sobre "Entidades" y deben aplicarse mediante el EntityManager. Estas sentencias son métodos del EntityManager que se aplican sobre la entidad y son:
- select : equivale al select de SQL pero se aplica sobre "entidades"
- find : equivale a la busqueda de una entidad basado en su PK
- persist : equivale a un insert.
- merge: equivale a un update.
- remove: equivale a un delete.
- refresh: equivale a una re-lectura de la entidad ( refresco desde la base de datos ).

No te confundas:
- en JDBC e IBatis se usan TABLAS relacionales.
- en JPA se usan "Entidades" que previamente han sido definidas dentro del archivo persistence.xml.
¡ Saludos !
martes, 10 de mayo de 2011
Sesion 05 : Introducción a JPA (Java Persistence API)
La historia de JPA se origina en dos frameworks de persistencia bastante utilizados: en el lado propietario existía TopLink mientras que en el lado “open” estaba Hibernate.
JPA es una especificación basada en el JSR 220 conocido como “Enterprise Java Bean 3.0” (http://jcp.org/en/jsr/detail?id=220 ).
Al ser una especificación (o un conjunto de API’s) está sujeta a diversas implementaciones de diversos fabricantes. La idea principal es que sea un Framework ligero, basado en POJOs y pueda enfrentar desafíos de arquitectura e integración en aplicaciones empresariales.
El concepto de “Entidad” fue introducido por Peter Chen en un documento llamado “The Entity-relationship model – Howard a unified view of data” publicado en “ACM Transactions on Database Systems” en el año de 1976
En dicho documento se describía a las entidades como cosas que tenían “atributos” y “relaciones” con la expectativa de que dichos atributos y relaciones pudieran ser almacenados en la base de datos.
¿ Cómo convertimos una clase POJO a Entidad JPA ? ... Hay 2 caminos :
- usando anotaciones
- usando el mapeo ORM en XML
El más fácil (a mi parecer) es usando anotaciones ... mira el ejemplo siguiente: Sólo necesitamos agregar la anotación @Entity y @Id (para indicar cual es la PK de la entidad ).
Ten en cuenta que por defecto JPA asume que la entidad está mapeada contra una tabla que se llama igual que la Clase Java, aunque hay formas de especificar el nombre de la tabla (usando la anotación @Table ).

Obviamente, falta configurar ( al igual que en Ibatis ) otro archivo para que durante el tiempo de ejecución, la JVM sepa que está trabajando con Entidades. Esto es materia del siguiente post.
Comenta que impresión tienes ahora sobre JPA.
viernes, 6 de mayo de 2011
Sesion 04 - Struts 2 y Validaciones
El framework de Struts2 proprociona facilidades de validación de los campos de un formulario en el lado del servidor (ojo que no es JavaScript que corre en el navegador).
El framework hace uso de dos Interfaces (implementadas por la clase ActionSupport) :
- Validateable : que contiene un único método cuya firma es void validate(). La clase ActionSupport contiene una implementación por defecto que permite validar mediante configuraciones basadas en XML o en anotaciones.
- ValidationAware: proporciona un grupo de métodos usados para recolectar mensajes de error relacionados a campos del formulario o propiedades de la clase Action en general. Tambien se emplea para recolectar mensajes informativos y determinar si se presentan errores.
Las dos interfaces colaboran dentro del workflow de Struts2, específicamente en el stack de interceptores: interceptor “validation” e interceptor “workflow”.
Si la validación es satisfactoria, se ejecuta el método respectivo de la clase Action invocada. En caso que la validación falle, se retorna el resultado denominado “input”.
Si no se define el resultado para “input”, el framework genera un error durante la ejecución.
En esta sesión veremos 3 formas de validar:
- Manualmente : implementando el código en el método "validate" dentro del Action.
- Usando XML : asociando cada Action con su archivo de validación XML.
- Generando validadores personalizados.
Existe un forma adicional que es utilizando "anotaciones".
Material de la sesión:
- Descarga el PDF aquí.
- Descarga la aplicación completa aquí. La aplicación debe funcionar tanto en Apache Tomcat como en IBM WAS sin mayor problema ( y no como sucedió en los labs ... mil disculpas por ello y veremos la forma de solucionarlo ).
Si deseas profundizar en el tema, por favor revisa la bibilografía recomendada en un post anterior.
Suscribirse a:
Entradas (Atom)