Fundamentos de Programación Orientada a Aspectos
Como su nombre lo indica, la Programación Orientada a Aspectos (AOP por sus siglas en inglés) es un tipo de programación que se basa en identificar y crear “aspectos”. La AOP no se contradice con el diseño y la programación orientada a objetos, en lugar de ello se complementan. De esta forma se debe ver a la AOP como el siguiente peldaño en la evolución natural de la programación orientada a Objetos dentro del área de Ingeniería de Software.
En AOP, incumbencias ortogonales a una aplicación como la seguridad y el rastreo (logging) se identifican como incumbencias que se cruzan y solapan con los sistemas. Esto debido a que siempre cortan múltiples unidades de modularidad (como paquetes y clases) a través de una aplicación. La idea de AOP es separar la lógica de esas incumbencias de tal forma que no se mezcle con la lógica funcional propia de una aplicación.
Por ejemplo en la figura se puede apreciar la implementación de un caché usando la programación orientada a Objetos (OOP). La lógica de caché ha sido centralizada en un módulo de tal forma que las llamadas a las funcionalidades del caché están embebidas dentro de los módulos clientes y mezcladas a lo largo de la aplicación.
Algunos problemas de esto son:
- El código es complejo y difícil de comprender permitiendo que se pierda la identificación de la incumbencia principal de la aplicación.
- El mantenimiento es difícil, pues cualquier trabajo de mantenimiento que involucre la implementación de una de las incumbencias puede afectar a las demás.
- El código es difícil de probar.
- La reusabilidad del código disminuye.
La Programación Orientada a Aspectos sirve para resolver estos problemas utilizando la “separación de incumbencias”. AOP ofrece otra forma de estructurar los programas por medio del ensamblaje de código que implementa cada incumbencia dentro de su propio módulo. Así, las incumbencias se modularizan en unidades de trabajo llamadas “aspectos”.
Los aspectos también permiten la encapsulación de los detalles de implementación de las incumbencias. A diferencia de las clases, los aspectos no sólo ocultan el cómo se ejecuta algo, sino también el cuándo se ejecuta.
En la figura se muestra la representación de la incumbencia de “caché” modularizada dentro de un aspecto. Los módulos núcleo no contienen ninguna llamada a las API’s del caché. De hecho, los módulos núcleo de la aplicación no están enterados del uso de caché.
Los elementos de AOP son:
- Los puntos de unión (Join points)
- Los puntos de corte (pointcuts)
- Los consejos (advices)
- Las declaraciones Intertipo (inter-type declarations)
- Los aspectos (aspects)
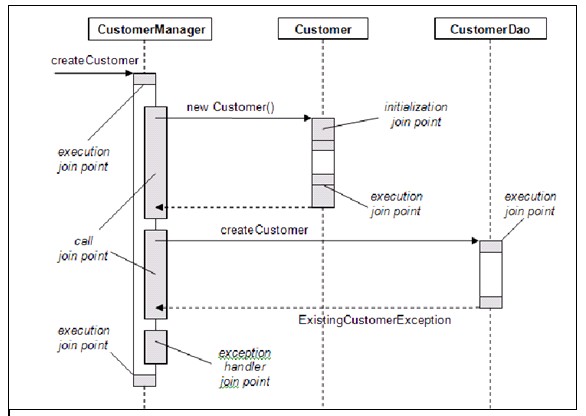
Los puntos de unión
Son puntos bien definidos durante la ejecución de la aplicación y en los cuales se puede aplicar una corte cruzado de incumbencias. Los puntos de unión disponible en general dependen de la herramienta AOP particular que se esté empleando. En el caso de AspectJ se tiene disponible: - La llamada a un método
- La ejecución de un método.
- La llamada a un manejador de excepción.
- La ejecución de un manejador de excepción.
- La llamada a un constructor.
- La ejecución de un constructor.
- La lectura de un campo.
- La escritura de un campo.
Debe notarse la diferenciación entre llamar y ejecutar un método. Los puntos de unión asociados a la llamada a un método tienen acceso a la información del contexto de ejecución antes de la llamada al método. Los puntos de unión asociados con la ejecución de un método tiene acceso a la información del contexto de ejecución dentro del cuerpo del método.
En el caso de AspectJ no se puede trabajar directamente con los puntos de unión. En lugar de ello se debe emplear los puntos de corte.
Puntos de Corte:
Para especificar dónde y cuándo se aplica el corte cruzado del código se debe declarar los puntos de corte. Un punto de corte selecciona un conjunto de puntos de unión. La siguiente tabla muestra los puntos de corte más empleados en AspectJ.
En AspectJ, se declara los puntos de corte por medio de los “aspectos”, clases o interfaces como se muestra en la figura siguiente:
Como cualquier otro objeto en Java, los puntos de corte pueden tener modificadores de acceso (público, privado, protegido o por defecto) para restringir el acceso a ellos.
AspectJ proporciona un amplio conjunto de operadores y caracteres comodines para permitir ajustar el ámbito de aplicación del punto de corte como sea requerido.
Consejos
Un consejo junta el código que se necesita aplicar junto con el punto de unión seleccionado por el punto de corte. Se coloca el código que se necesita ejecutar dentro del consejo y se especifica cuando se requiere la ejecución respecto al punto de unión.
Existen tres elecciones para los consejos generales como se muestra en la tabla siguiente:
Aqui un ejemplo de consejos aplicados a diversos puntos de unión:
Declaraciones Inter-tipos
AspectJ permite agregar nuevos miembros (métodos o campos) a clases o tipos existentes, así como para manipular jerarquías de herencias de una manera controlada.
Esas declaraciones adicionales contenidas dentro de aspectos son llamadas declaraciones Inter-tipos. Para los usuarios de estas clases afectadas, los nuevos miembros declarados aparecen como si ellos hubieran sido implementados por la clase o tipo original.
Aspectos
Cuando se emplea AspectJ, el lenguaje de programación Java se extiende con la definición de los aspectos. El aspecto se define de la misma forma en que se define una clase.
Un aspecto permite poner juntos a:
- Los puntos de corte.
- Los consejos.
- Las declaraciones inter-tipos.
Al igual que las clases Java, los aspectos pueden tener atributos y métodos (estáticos o no). También se puede crear aspectos abstractos como las clases, extender los aspectos o crear nuevos.
Un incumbencia (concern) es un área particular de interés en una aplicación.